Deep Video Generation, Prediction and Completion of Human Action Sequences
Supplementary Material
Real-world Examples
We use unseen reference images in the first column (arbitrary unrelated actions) to generate Direction/Greeting actions. 1st, 2nd and 3rd row: UCF-101 results. 4th row: Forrest Gump results. This is the full video for Fig. 2 in paper.
Reference Image
Ours
Qualitative Comparison
Note: Each following section corresponds to a generation task, namely video generation, video prediction and video completion.
In each task, first we present results on Human 3.6m dataset. Columns named "Real" stands for real data (for your reference). Columns named "Input-n" stands for input frames where n is the frame number used (e.g. “Input-1” means the 1st frame in a video is used as input/constraint). The other columns show the qualitative results of each method. For our method we also show our pose sequence results, denoted as “Ours-Pose”. Each row corresponds to an action class, from top to bottom: Walking, Direction, Greeting, Sitting, Sitting Down.
Then we present our results on UCF-101 dataset to illustrate our model's effectiveness in real-world. Input frames are labeled in the same fashion. Video action class includes JumpingJack, JumpingRope, TaiChi, which will be labeled accordingly.
Video Generation - Human 3.6m
Real
VGAN
Ours
Ours-Pose
Real
VGAN
Ours
Ours-Pose
Real
VGAN
Ours
Ours-Pose
Real
VGAN
Ours
Ours-Pose
Real
VGAN
Ours
Ours-Pose
Video Generation - UCF-101
JumpingJack
JumpingRope
TaiChi
Video Prediction - Human 3.6m
Input-1
Input-3
Input-2
Input-4
PredNet
PoseVAE
MS-GAN
Ours
Ours-Pose
Input-1
Input-3
Input-2
Input-4
PredNet
PoseVAE
MS-GAN
Ours
Ours-Pose
Input-1
Input-3
Input-2
Input-4
PredNet
PoseVAE
MS-GAN
Ours
Ours-Pose
Input-1
Input-3
Input-2
Input-4
PredNet
PoseVAE
MS-GAN
Ours
Ours-Pose
Input-1
Input-3
Input-2
Input-4
PredNet
PoseVAE
MS-GAN
Ours
Ours-Pose
Video Prediction - UCF-101
Input-1
Input-3
Input-2
Input-4
JumpingJack
Input-1
Input-3
Input-2
Input-4
JumpingRope
Input-1
Input-3
Input-2
Input-4
TaiChi
Video Completion - Human 3.6m
Input-1
Input-50
cond-VGAN
Ours
Ours-Pose
Input-1
Input-50
cond-VGAN
Ours
Ours-Pose
Input-1
Input-50
cond-VGAN
Ours
Ours-Pose
Input-1
Input-50
cond-VGAN
Ours
Ours-Pose
Input-1
Input-50
cond-VGAN
Ours
Ours-Pose
Video Completion - UCF-101
Input-1
Input-50
JumpingJack
Input-1
Input-50
JumpingRope
Input-1
Input-50
TaiChi
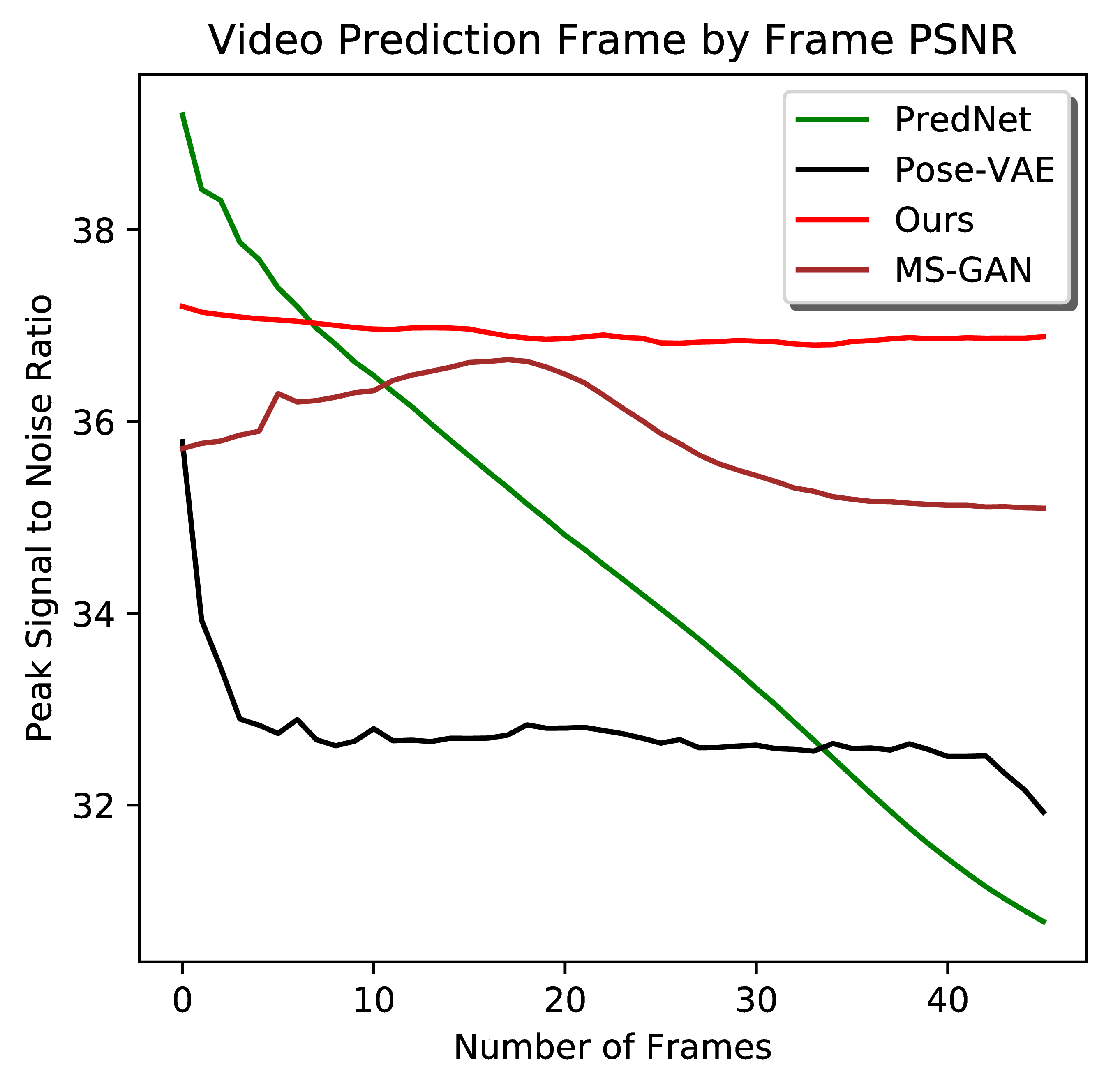
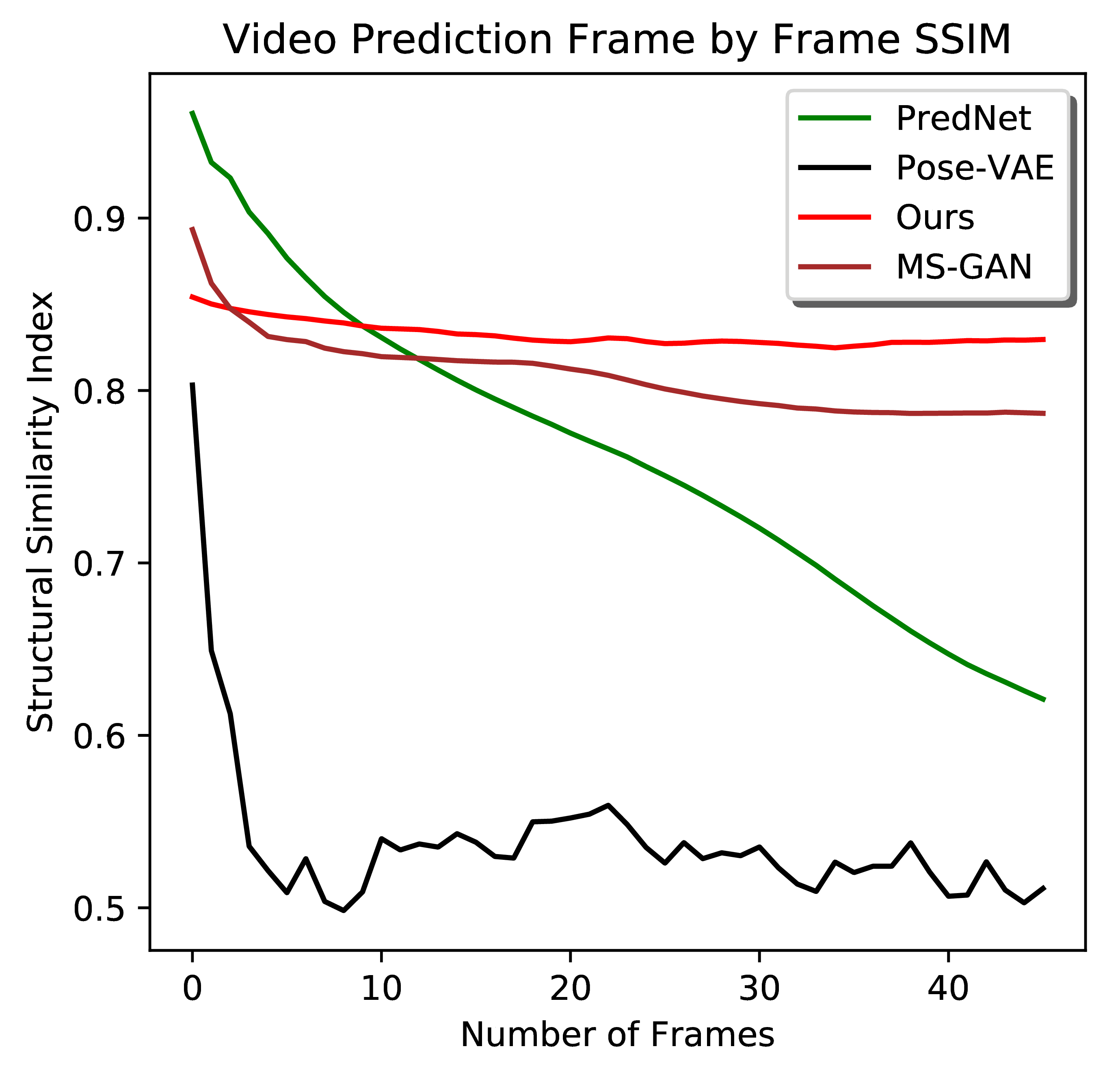
Quantitative Comparison
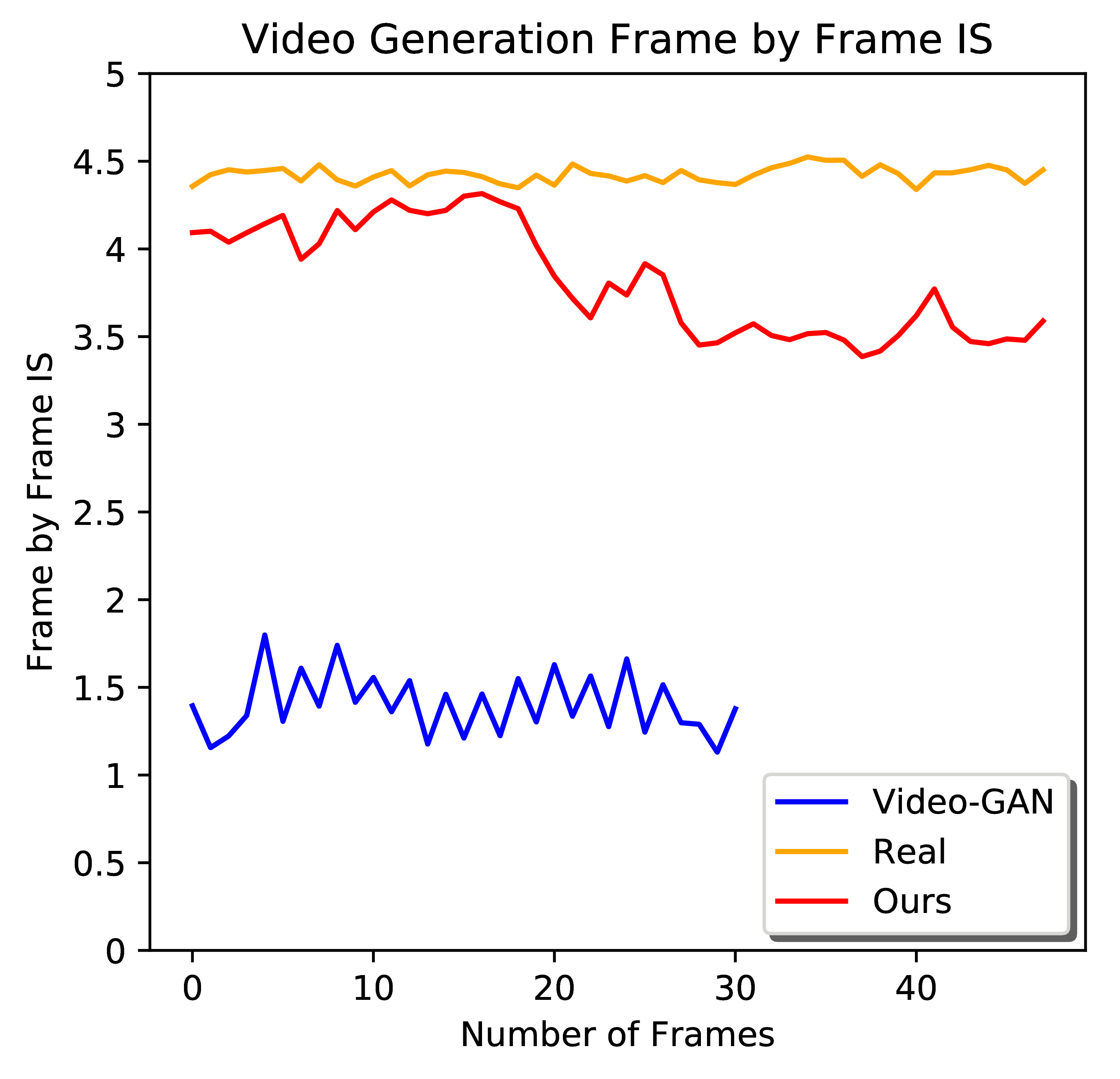
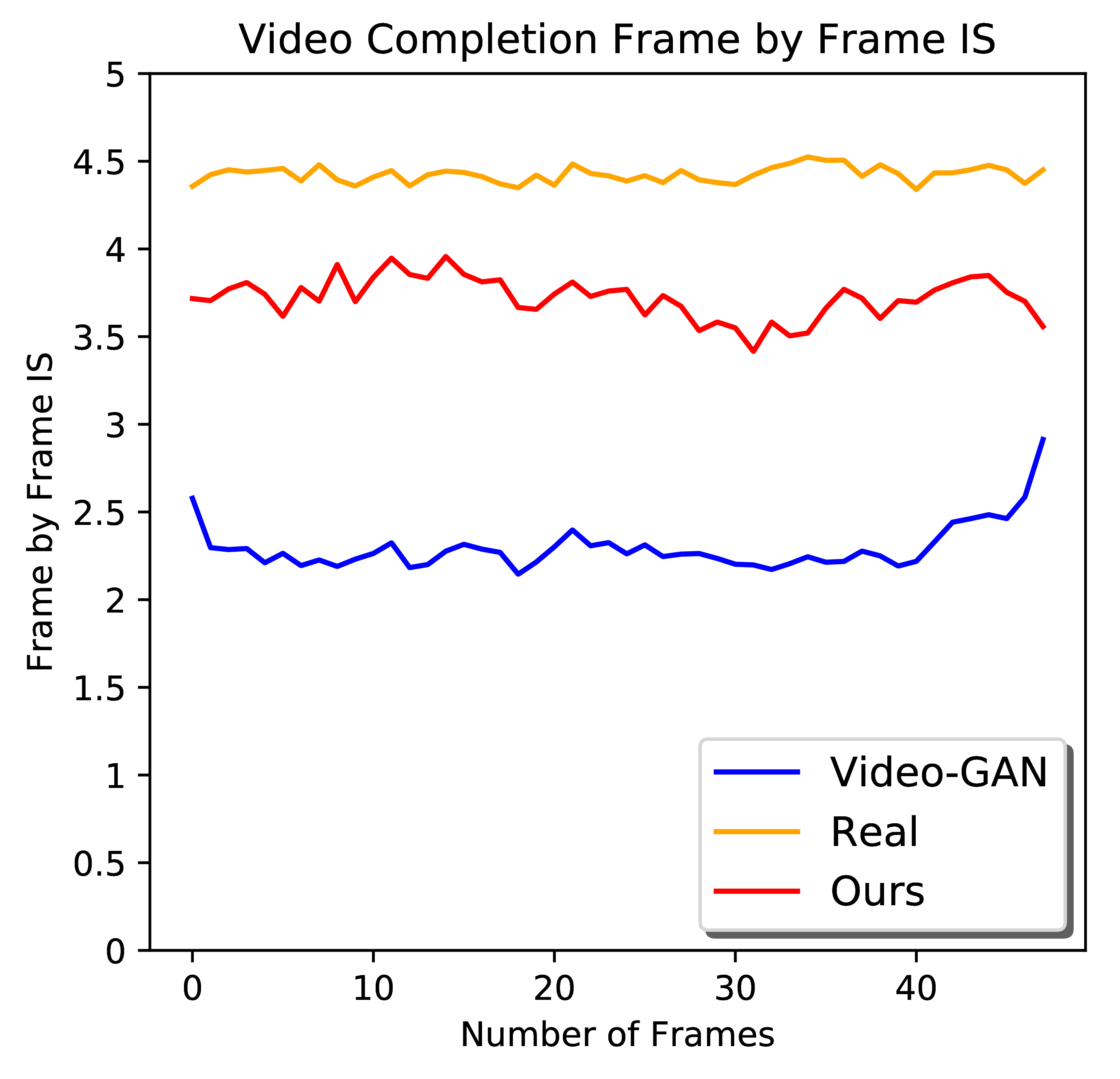
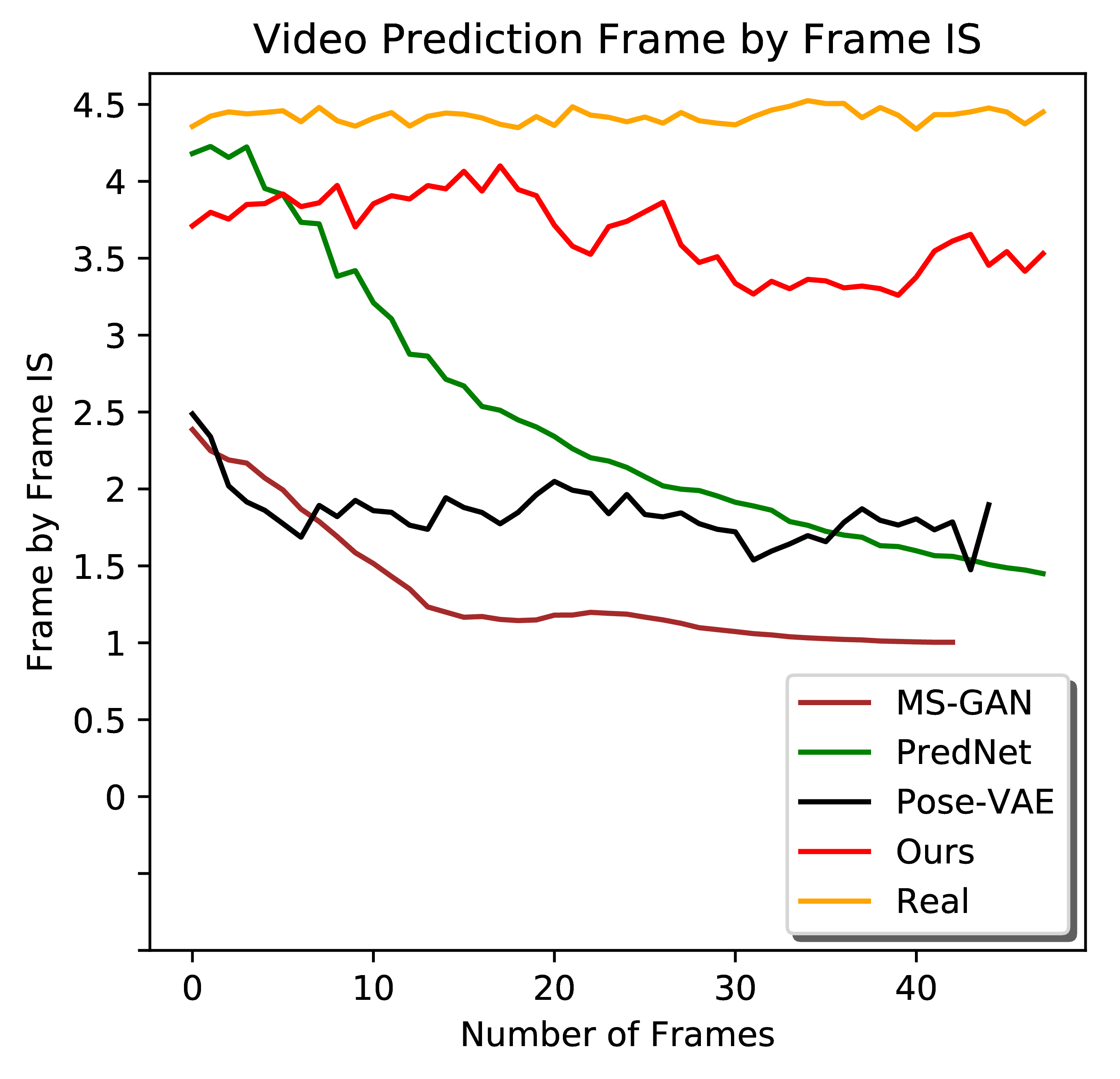
From left to right: Frame-by-frame Inception Score for video generation, completion, prediction. Frame-by-frame PSNR and SSIM for video prediction. Larger quantitative comparison figures for your reference.
Illustration of Our Pipeline
Video Generation Pipeline
Video Prediction Pipeline
Video Completion Pipeline
$z_0 \sim \mathcal{U}(-1, 1)$
$z \sim \mathcal{N}(0, 1)$
Input-1
Input-2
Input-3
Input-4
Input-1
Input-50
$z_0 + z\: (concatenation)$
stacked hourglass pose estimation
stacked hourglass pose estimation
$z_0 \in \mathbb{R}^{8}, z \in \mathbb{R}^{24}$
Pose-1
Pose-2
Pose-3
Pose-4
Pose-1
Pose-50
Pose Sequence Generation Process
Constrained Pose Sequence Generation Process
Constrained Pose Sequence Generation Process
Skeleton to Image
Skeleton to Image
Skeleton to Image
Implementation Details
We use Adam Solver at a learning rate of $0.001$ for training Single Pose Generator and 5e-5 for training Pose Sequence Generator, both decaying by 0.5 after 30 epochs with $\beta_1$ being 0.5 and $\beta_2$ being 0.9. We set the weight of gradient penalty to be 10 and the weight of L2 regularization term for generated latent vector shift to be 0.1.
For skeleton-to-image network, We train our network with Adam Solver at a learning rate of 0.001 and $\beta_1$ of 0.9. For the feature matching loss we set $\lambda$ = 0.01. Our architecture details are shown in Fig. 7. In the encoder we have $8$ convolution layers with $5\times5$ filter size, alternating stride of $2,1,2,1,2,1,2,1$ and same padding. In the decoder we have $3$ $(upsample, conv, conv)$ modules followed by $1$ $(upsample, conv)$ module, where $upsample$ stands for nearest neighbor resize with $scale factor=2$ and $conv$ stands for convolution layer with $5\times5$ filter size and $1$ stride size with same padding.